
I hadn’t looked at using a decision tree from the scikit-learn (scikit for short) library for several months, so I figured to do an example. Before I go any further: I am not a big fan of decision trees and this example reinforces my opinion.
I used one of my standard datasets for binary classification. The data looks like:
1 0.24 1 0 0 0.2950 0 0 1 0 0.39 0 0 1 0.5120 0 1 0 1 0.63 0 1 0 0.7580 1 0 0 0 0.36 1 0 0 0.4450 0 1 0 . . .
Each line of data represents a person. The fields are sex (male = 0, female = 1), age (normalized by dividing by 100), state (Michigan = 100, Nebraska = 010, Oklahoma = 001), annual income (divided by 100,000), and politics type (conservative = 100, moderate = 010, liberal = 001). The goal is to predict the gender of a person from their age, state, income, and politics type. The data can be found at: https://jamesmccaffrey.wordpress.com/2022/09/23/binary-classification-using-pytorch-1-12-1-on-windows-10-11/.
It isn’t necessary to normalize age and income. Converting categorical predictors like state and job-type is conceptually tricky, but the bottom line is that in most scenarios it’s best to one-hot encode rather than categorical encode. Ordinal data like low = 0, medium = 1, high = 2 can be ordinal-encoded.
The scikit documentation states that for binary classification, the variable to predict should be encoded as -1 and +1. However, one of the documentation examples uses 0 and 1 which is more consistent with other binary classification algorithms. In fact, it’s possible to use text labels, such as “M” and “F”, for the target class too. The scikit documentation has quite a few inconsistencies like this.
The key lines of code are:
md = 4 # depth
print("Creating decision tree with max_depth=" + str(md))
model = tree.DecisionTreeClassifier(max_depth=md,
random_state=1)
model.fit(train_x, train_y)
print("Done ")
Decision trees are highly sensitive to overfitting. If you set a large max_depth you can get 100% classification on training data but the accuracy on test data and new previously unseen data will likely be very poor.
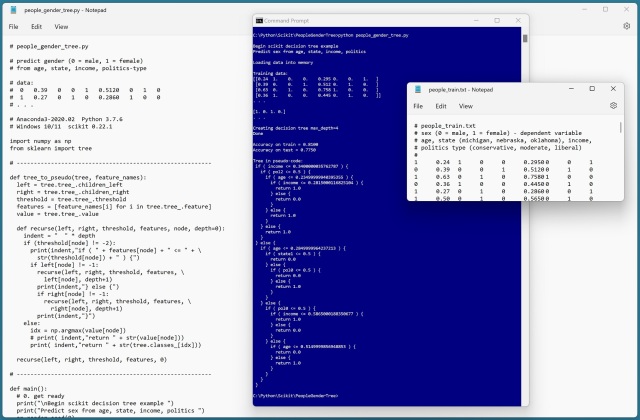
I wrote a custom tree_to_pseudo() function that displays a tree in text format. Note: I kludged the function together from examples I found on the Internet — the code is very, very tricky. The first part of the output of tree_to_pseudo() looks like:
if ( income "lte" 0.3400 ) {
if ( pol2 "lte" 0.5 ) {
if ( age "lte" 0.235 ) {
if ( income "lte" 0.2815 ) {
return 1.0
} else {
return 0.0
}
} else {
return 1.0
}
} else {
return 1.0
}
} else {
. . .
There is also a built-in tree.export_text() function that gives similar results:
|--- income "lte" 0.34 | |--- pol2 "lte" 0.50 | | |--- age "lte" 0.23 | | | |--- income "lte" = 0.28 | | | | |--- class: 1.0 . . .
Anyway, the demo was a good refresher for me.

A few years ago some researchers in the UK did an experiment where they determined that people can identify the gender of a person solely by how they walk. Fashion models extend this idea to exaggerated walking styles. Left: The long stride. Center: The walk on a straight line. Right: The sway.
Demo code. Replace “lte” with Boolean less-than-or-equal operator. The data can be found at jamesmccaffrey.wordpress.com/2022/09/23/binary-classification-using-pytorch-1-12-1-on-windows-10-11/.
# people_gender_tree.py
# predict gender (0 = male, 1 = female)
# from age, state, income, politics-type
# data:
# 0 0.39 0 0 1 0.5120 0 1 0
# 1 0.27 0 1 0 0.2860 1 0 0
# . . .
# Anaconda3-2020.02 Python 3.7.6
# Windows 10/11 scikit 0.22.1
import numpy as np
from sklearn import tree
# ---------------------------------------------------------
def tree_to_pseudo(tree, feature_names):
left = tree.tree_.children_left
right = tree.tree_.children_right
threshold = tree.tree_.threshold
features = [feature_names[i] for i in tree.tree_.feature]
value = tree.tree_.value
def recurse(left, right, threshold, features, node, depth=0):
indent = " " * depth
if (threshold[node] != -2):
print(indent,"if ( " + features[node] + " lte " + \
str(threshold[node]) + " ) {")
if left[node] != -1:
recurse(left, right, threshold, features, \
left[node], depth+1)
print(indent,"} else {")
if right[node] != -1:
recurse(left, right, threshold, features, \
right[node], depth+1)
print(indent,"}")
else:
idx = np.argmax(value[node])
# print(indent,"return " + str(value[node]))
print(indent,"return " + str(tree.classes_[idx]))
recurse(left, right, threshold, features, 0)
# ---------------------------------------------------------
def main():
# 0. get ready
print("\nBegin scikit decision tree example ")
print("Predict sex from age, state, income, politics ")
np.random.seed(0)
# 1. load data
print("\nLoading data into memory ")
train_file = ".\\Data\\people_train.txt"
train_xy = np.loadtxt(train_file, usecols=range(0,9),
delimiter="\t", comments="#", dtype=np.float32)
train_x = train_xy[:,1:9]
train_y = train_xy[:,0].astype(int)
test_file = ".\\Data\\people_test.txt"
test_xy = np.loadtxt(test_file, usecols=range(0,9),
delimiter="\t", comments="#", dtype=np.float32)
test_x = test_xy[:,1:9]
test_y = test_xy[:,0].astype(int)
np.set_printoptions(suppress=True)
print("\nTraining data:")
print(train_x[0:4])
print(". . . \n")
print(train_y[0:4])
print(". . . ")
# 2. create and train
md = 4
print("\nCreating decision tree max_depth=" + str(md))
model = tree.DecisionTreeClassifier(max_depth=md,
random_state=1)
model.fit(train_x, train_y)
print("Done ")
# 3. evaluate
acc_train = model.score(train_x, train_y)
print("\nAccuracy on train = %0.4f " % acc_train)
acc_test = model.score(test_x, test_y)
print("Accuracy on test = %0.4f " % acc_test)
# 3b. use model
# print("\nPredict age 36, Oklahoma, $50K, moderate ")
# x = np.array([0.36, 0,0,1, 0.5000, 0,1,0],
# dtype=np.float32)
# predicted = model.predict(x)
# print(predicted)
# 4. visualize
print("\nTree in pseudo-code: ")
tree_to_pseudo(model, ["age", "state0", "state1", "state2",
"income", "pol0", "pol1", "pol2"])
# 4b. use built-in export_text()
# recall: from sklearn import tree
pseudo = tree.export_text(model, ["age", "state0", "state1",
"state2", "income", "pol0", "pol1", "pol2"])
print(pseudo)
# 4c. use built-in plot_tree()
import matplotlib.pyplot as plt
tree.plot_tree(model, feature_names=["age", "state0",
"state1", "state2", "income", "pol0", "pol1", "pol2"],
class_names=["male", "female"])
plt.show()
# 5. TODO: save model using pickle
if __name__ == "__main__":
main()
 .NET Test Automation Recipes
.NET Test Automation Recipes Software Testing
Software Testing SciPy Programming Succinctly
SciPy Programming Succinctly Keras Succinctly
Keras Succinctly R Programming
R Programming 2024 Visual Studio Live Conference
2024 Visual Studio Live Conference, in Las Vegas") 2024 Predictive Analytics World
2024 Predictive Analytics World") 2024 DevIntersection Conference
2024 DevIntersection Conference 2023 Fall MLADS Conference
2023 Fall MLADS Conference 2022 Money 20/20 Conference
2022 Money 20/20 Conference 2022 DEFCON Conference
2022 DEFCON Conference 2022 G2E Conference
2022 G2E Conference 2023 ICGRT Conference
2023 ICGRT Conference 2024 CEC eSports Conference
2024 CEC eSports Conference 2024 ISC West Conference
2024 ISC West Conference
Pingback: Binary Classification Using a scikit Decision Tree -- Visual Studio Magazine